マイクロサービス・アーキテクチャ
「マイクロサービス・アーキテクチャ」とはDX時代の高速ウェブアプリケーション開発を支えるAPIマッシュアップ技法を使った開発手法。それがどのようなものかを一言で定義するなら、「複数の独立した機能を組み合わせることで、一つの処理を実現するアーキテクチャ」であると言えます。ポイントは、一つの処理を実現するのが一つの機能ではなく、複数の機能であるというところです。
マイクロサービスのメリット

3層構造中心のレガシーシステム、一つのビジネスロジック内でコンポーネントが複数存在し、UIはコンポーネントを呼び出す(API)ことで成立していた。また各コンポーネントの関連は密結合であり、DevOpsを進めていく上で局所化した改変を実施することが出来なかった。
一方マイクロサービスでは分割されたビジネスロジックがそれぞれ疎結合となり、UIはビジネスロジック単位を呼び出す(このAPIを”マイクロサービス”と言う)ことで、API数減少及びAPIの連鎖を意識することなくUIは開発が進められるようになる。マイクロサービス化するメリットは独立性、保守性、拡張性、可用性、再利用性で真のDevOpsを支えます。
デザインパターン
マイクロサービス利点を実現するためには、ひとつひとつのシステム構成要素に対する細かなデザインパターンの適用が必要となります。言い換えると、マイクロサービスを適用したシステムとは、「複数のデザインパターンの集合体」です。
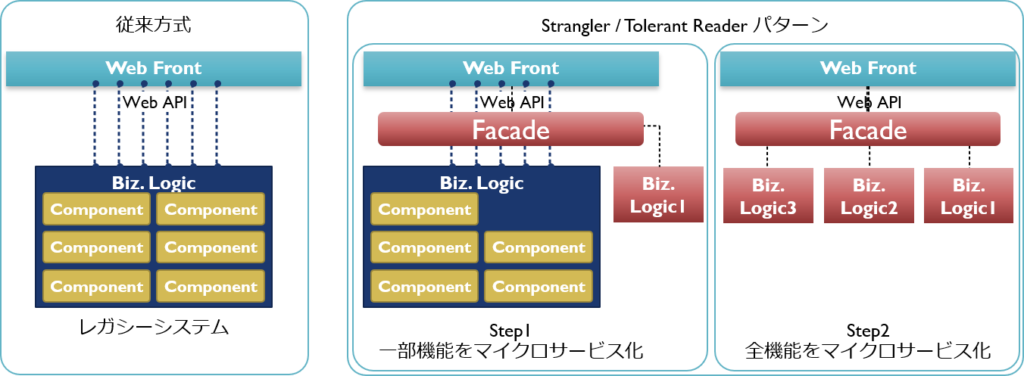
StranglerパターンとTolerant Readerパターン
レガシーシステムをビックバンではなく、徐々にマイクロサービスに置き換えていくデザインパターンです。本パターンの特徴はFacade(ファザード)と呼ばれる前処理クラス(サービス)を用意して、ビジネスロジックを隠蔽することです。このパターンによりUI側への影響を抑えた上でレガシーシステムをマイクロサービス化可能です。
また、このStranglerパターンを適用する際に、Tolerant Readerパターンも併用すると効果的です。呼び出す側(Reader)が、呼び出される側の変更をできるだけ「柔軟に受け止められる」作りにしておくという考え方です。
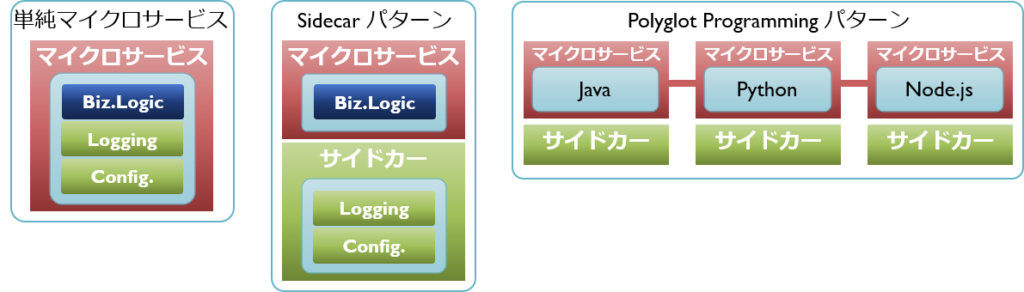
SidecarパターンとPolyglot Programmingパターン
マイクロサービスはそれぞれのサービスが独立し、一般にRestFull APIで繋がります。そのため、個々のサービスが内部でどのような技術(構成や言語など)で作成されるかは自由です。一方で、思い思いに作成されたサービスたちは、主処理である業務ロジックだけでなく、さまざまな周辺処理(ログ出力や設定情報など)までそれぞれの技術にあわせた個別実装が必要になってしまいます。
この課題を解決するのがSidecarパターンです。主処理であるアプリケーションに別のコンポーネントを付属させる構造とします。このパターンを適用することにより、各サービスは共通的な周辺処理をそのコンポーネントに任せられます。その結果、開発者は主処理の実装だけに専念できるようになります。
上記によって実現しやすくなるのがPolyglot Programmingパターンです。従来は、システム全体で1種類のプログラミング言語と、SQLのようなデータストア用のドメイン固有言語という構成が定番でした。しかしそれでは、最大公約数的な言語選択しかできず、個々のサービスにとって最適とは言えません。多様な言語選択により、業務特性や要件、メンバーのスキルセットにあわせた最適化を行うことができる。
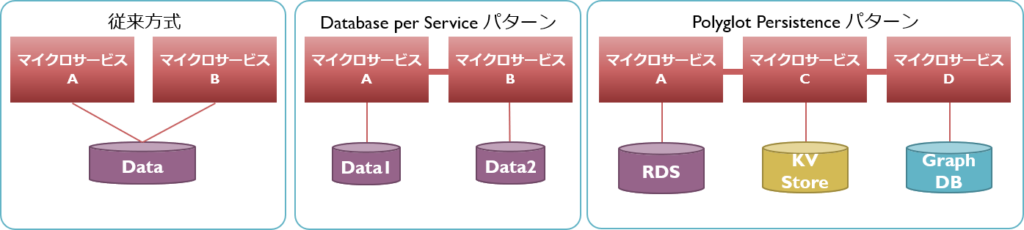
Database per ServiceパターンとPolyglot Persistenceパターン
多くのレガシーシステム場合、複数の機能がひとつのデータベースを操作します。マイクロサービスに分割した後もそのままだと、データ構造変更時に関連サービスへの影響考慮が必要となり、大量の回帰テストを実施する事態となります。また、多くのレガシーシステムはRDBを採用していますが、異なるデータストアを適用したくとも影響の規模が大きすぎ、採用を見送るケースも多いでしょう。
そのような事態を避けるためにとられるのが、Database per Serviceパターンです。その名の通り、各データベースにアクセスするサービスは1個に限定します。他のサービスから参照・更新する際は、そのデータを管轄するサービスを介して行います。これによりデータそのものは隠蔽され、データ構造やデータストアの変更による影響を1つのサービスのみに局所化できます。
なお、サービス特性にあわせて個別のデータストアを適用すべきという考え方は、Polyglot Persistence(多言語永続化)と呼ばれます。先に説明したPolyglot Programmingと同じように、データストアもまたパフォーマンスの重要性やトランザクション処理の要否など、サービスごとの特性や要件に合ったものを採用すべきという考え方で、こちらもシステムの最適化において重要です。
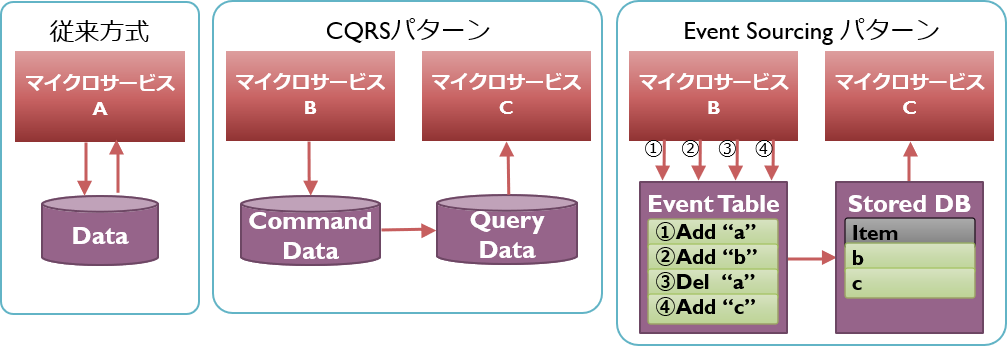
CQRSパターンとEvent Sourcingパターン
データベース操作はCRUDという4種に分類されますが、そのうちの書き込みを意味するCUDと読み込みを意味するRでは、重視すべきことや検討すべきことが大きく異なります。具体的には、書き込みでは更新性能やデータの整合性が重視され、それらを確保するためのトランザクション制御やロックの確保などが検討されます。一方で読み込みの際は、参照性能や返却値の加工が重視され、INDEXの定義や読み込みデータによる値の計算処理などが検討されます。
加えて、書き込みと読み込みの性能要件や処理負荷が大きく異なるサービスの場合、パフォーマンスチューニングやスケーリングの検討を同じデータストアに対して行うことは、最適化を妨げる要因ともなります。
それらの課題を持つサービスに対し導入されるのがCQRS(Command Query Responsibility Segregation)パターンです。書き込み(=Command)と読み込み(=Query)でサービス(及びデータストア)を分離します。これにより書き込み側と読み込み側は、それぞれの処理に最適な実装及びデータ構造をとることができます。性能要件が異なれば、別の種類のデータストアを適用することや、配置先のハードウェアを分けることもできます。
なお、多くの場合CQRSと同時に適用されるのがEvent Sourcingパターンです。このパターンで書き込み側のサービスが行うのは、一般的に行われるように「データそのものを更新する」のではなく、「データを更新するという命令を保存する」という行為です。
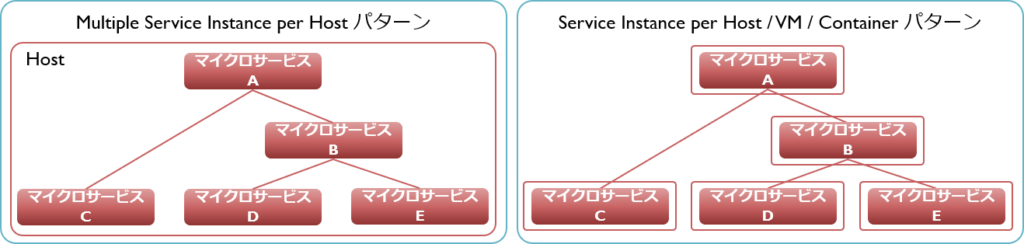
Service Instance per Host / VM / Containerパターン
1つの環境に複数のサービスを載せること(Multiple Service Instance per Host)は、マイクロサービスの持つ多くのメリットを犠牲にします。それぞれのサービスが全体の実行環境に影響を及ぼすため、CPU使用状況の監視が難しくなったり、あるサービスのデプロイ(配置作業)が他のサービスに影響してしまいかねない、といった点がそれです。中でも課題となるのは、サービスごとのスケーリングができなくなるということでしょう。個々のサービスごとに適切なハードウェア構成をとることができず、システム全体に合わせた構成をとらざるを得なくなります。
Service Instance per Hostパターンを適用することで、サービス間の独立性が保たれ、上記の問題を解決できます。監視対象やデプロイは干渉しなくなり、スケーリングもそのサービスに特化した対応ができるようになるため、拡張性が向上します。
さらに、仮想マシン技術を用いれば、リソースをより無駄なく活用できます(Service Instance per VM)。そして、仮想化をより小さい単位で実現するコンテナ型仮想化技術なら、より一層リソース効率を高めることができるでしょう(Service Instance per Container)。
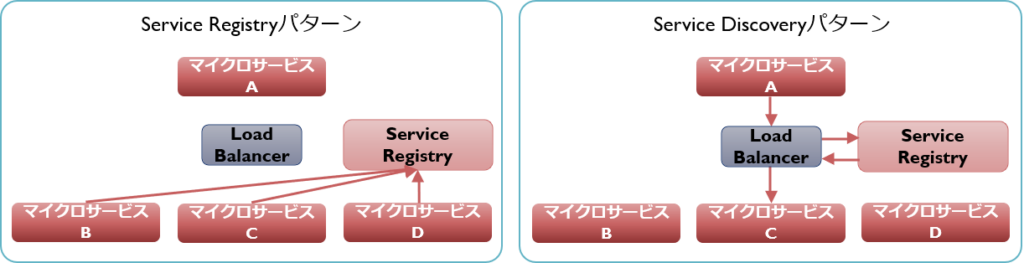
Service RegistryパターンとService Discoveryパターン
各サービスはその接続先を特定できるIPアドレスなどの情報を持っており、呼び出し元はその値によって対象のサービスにアクセスします。しかし、その値を呼び出し元が直接保持してしまうと、接続先が変わるたびに呼び出し元の修正が必要になってしまいます。また、負荷分散のために同一のサービスを複数コピー配置して使用する場合や、さらには仮想化技術によりアクセス量にあわせて動的にその数を増減するケースもあるため、接続先の特定には柔軟性を持たせる必要があります。
そこで、各サービスの接続先のRegistryを管理する機能を配置し、呼び出し元はそれを経由して相手先のサービスをDiscoveryする手法がとられます。これにより、接続先情報が変わっても呼び出し元に影響することはなく、また各サービスの配置状況にあわせて適切な接続先が使用されることとなります。
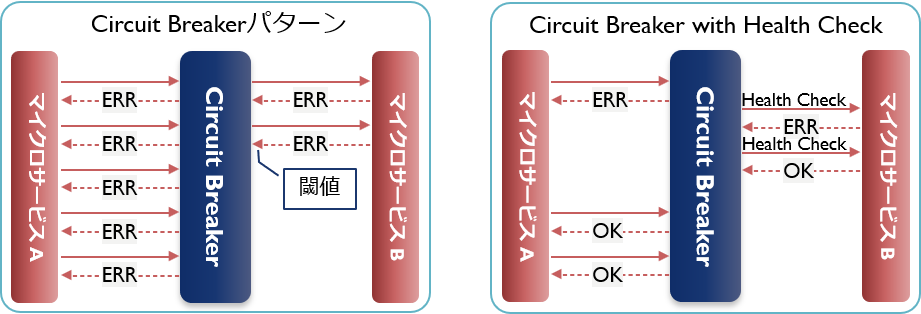
Circuit BreakerパターンとHealth Checkパターン
各サービスへの呼び出しは、時に失敗します。その原因が、ネットワーク接続の瞬断や、短期的なビジー状態などによるものであれば、自動的に修正されることを期待し、単純リトライなどの仕組みに任せればよいでしょう。しかし、予期しない不具合や修正に時間がかかるバグが原因であった場合は、繰り返しリトライしたりタイムアウトさせる仕組みをそのまま適用してしまうと、問題をさらに増やしてしまう要因になりかねません。
それらを防ぐための機構がCircuit Breakerです。呼び出しを失敗した数や頻度などをもとに閾値を設定しておき、それを超えたら「ブレーカーを落とす」という仕組みです(以降、そのサービスへのアクセスをさせずに手前でエラーを返す)。これにより、ユーザーは速やかにエラーを受け取ることができるようになり、システムはリトライによる負荷を軽減できます。
なお、ブレーカーの先にあるサービスに対しては、定期的に死活監視(Health Check)を行い、復帰を確認できたら通常の処理に戻します。
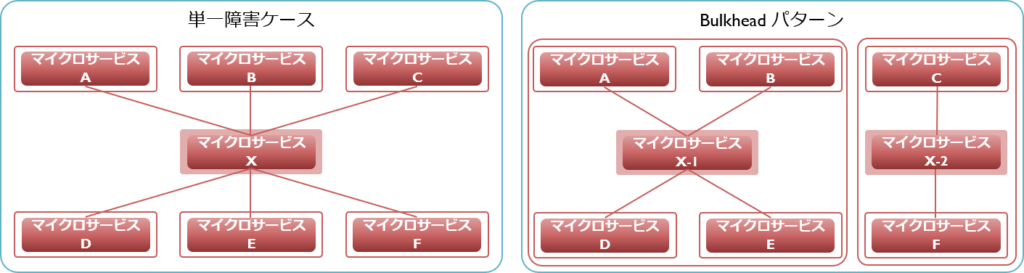
Bulkheadパターン
ある特定のサービスに不具合が発生しただけで、システム全体が使用できなくなることがあります。一例としては、あるシステムが持つ大半の機能から呼び出されるようなサービスがある場合に、そのサービスがダウンしたケースがそれにあたるでしょう(一般に「単一障害点」と呼ばれる箇所)。その他の例としては、あるサービスが不具合により暴走してCPUリソースを過剰消費してしまい、その結果システム全体の処理に悪影響を及ぼすというケースもあります。
先の例の1つ目でいうと、単一障害点となっているサービスを物理的に別々のサーバーにコピーすることで冗長化し、呼び元によって使用先を振り分ければ、サーバーの違いが「障壁」となり一方のサーバーが故障しても他方を使う処理には影響がありません(先に説明した仮想化技術やService Registry / Service Discoveryを使えば、さらに構成は柔軟になります)。2つ目の例でいえば、サービスによって使用するCPUを特定させることで、その他のCPUリソースへの影響をとどめることができます。
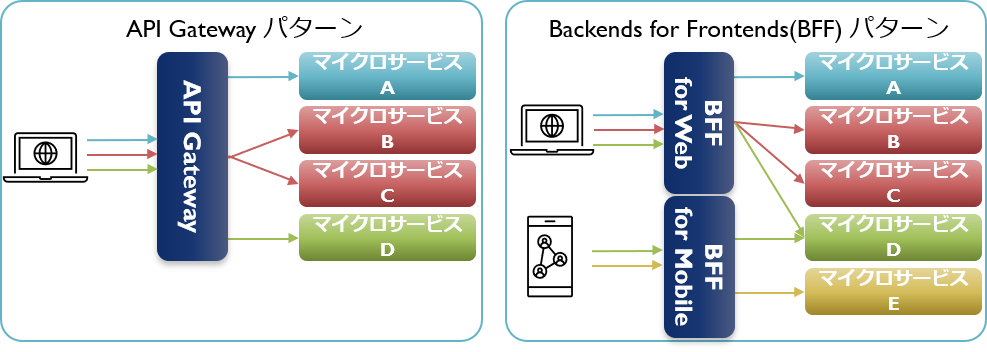
API GatewayパターンとBackends for Frontendsパターン
マイクロサービスが適用されたシステムは機能ごとにサービス分割されます。そのため、Webブラウザやスマホアプリなどのクライアントがシステムに接続する場合、クライアントが指定した各機能に対応したサービスが呼び出されます。その際、クライアントが直接個別のサービスを呼び出す構成をとってしまうと、いくつかの課題が発生します。
例えば、サービスの構成を変更するようなリファクタリングを試みる場合は、サービスだけでなく各クライアント側も修正が必要となるケースが出てきます。また、クライアントが求める1つの処理が複数のサービスで実現される場合、ネットワークを隔てた機能間で複数回のやりとりが必要となり、性能劣化の一因となります。その他には、1つ1つのサービスを直接公開することになるため、個別に認証やSSLといったセキュリティ対応が必要となるなど、サービスが複雑化する要因ともなります。
それらの問題は、サーバー側にAPI Gatewayと呼ばれる機能を配置し、全てのクライアントはその機能を通してサービスにアクセスする構造とすることで解決できます。
まず、サービスのリファクタリングはAPI Gatewayに隠蔽された裏側で行われるため、クライアントへの影響はありません。また、複数回のサービス呼び出しが必要な場合でも、サーバー側に配置されたAPI Gatewayがそれを行うことで、クライアント・サーバ間のネットワーク処理の増加も避けられます。そして公開されるのはAPI Gatewayのみとなるため、セキュリティ対応などもそちらで一元化でき、各サービスは業務処理に専念できます。
他には、API Gatewayを採用することによりクライアント側の処理がシンプルになるため、新たなクライアントが増えた場合でも既存のサービスを再利用しやすくなるというメリットもあります。
多数のクライアントからの処理を1つのAPI Gatewayで処理する構造にしてしまうと、個別のクライアント向けの処理がそこに集約され、結果としてその機能がモノリスのように肥大化してしまう場合があります。それでは、これまでに説明してきたマイクロサービスの利点の多くが失われてしまいます。
その対策として、個別のAPI Gatewayを作成するという考え方がBackends for Frontends(クライアントごとのバックエンド)です。略してBFFと呼ばれます。BFFを採用することにより、API Gatewayの持つ特長をそのまま活かしながら、その肥大化を避けることができます。
課題
マイクロサービスが全ての業務に必ずしも向いている訳ではありません。マイクロサービスの利点は一方で欠点でもあります。ビジネスロジック間は完全疎結故に、その間は通信に委ねられるので、これまでのシステムと比較してパフォーマンスはネットワークに依存します。またビジネスロジック間のインタフェースは非同期を推奨する故に、レスポンスのステータスとは異なりデータロストの可能性を秘めています。マイクロサービスの適用を考える際は”トランザクション保障”の可否を第一に考慮しなければなりません。
本ページは(株)翔泳社「これなら分かる!マイクロサービス(活用編)~そのアーキテクチャを実現するデザインパターンを一気に学習」を再利用しています。